















 不開放訂購
不開放訂購-



改變世界的九大演算法:讓今日電腦無所不能的最強概念
- 作者:約翰.麥考米克(John MacCormick)
- 出版社:經濟新潮社
- 出版日期:2014-08-19
- 定價:360元
-
購買電子書,由此去!
分類排行
-
矽谷最危險的公司.Palantir:一家AI國防巨獸,改變世界權力分布與科技走向

-
麥肯錫教企業這樣用AI數位轉型

-
持續買進:資料科學家的投資終極解答,存錢及致富的實證方法

-
工作者的AI共智模式:讓AI成為第二專長,加速專業升級,重塑競爭優勢

-
原子習慣WORKBOOK【官方版‧附練習別冊】

-
簡報的技術【限量作者親筆簽名版】

-
思考致富(暢銷80年經典版)百萬富翁締造者、成功學大師——拿破崙.希爾代表作,改變3億人命運,暢銷逾8000萬冊,與卡內基《人性的弱點》齊名

-
世界上最神奇的24堂課:啟發比爾.蓋茲創業原力,矽谷祕傳70年禁書,潛能激發必讀經典,「祕密」書中引用多達16次(暢銷百年經典 全新譯本)

-
Curation策展的時代:為碎片化資訊找到連結

-
一美元的全球經濟之旅:從美國沃爾瑪、中國央行到奈及利亞鐵路,洞悉世界的運作真相【暢銷紀念版】

內容簡介
◆榮獲美國出版人協會(Association of American Publishers)電腦資訊科學最佳書籍獎
電腦網路技術無所不在:每天,我們從海量的資訊中搜尋到所要的資訊、我們上傳照片到臉書上、我們運用公鑰加密來傳送私人資訊例如信用卡號碼等等、我們使用數位簽章來確認所造訪的網站的真偽……
這本書介紹了讓電腦網路世界得以運作,塑造今日人類生活的九種最重要的演算法(algorithm)。作者挑選這九大演算法的標準是:
1.每天會被一般電腦使用者用到的演算法。
2.必須能解決現實世界的具體問題。
3.主要是與資訊科學理論有關的演算法。
4. 美、簡潔、優雅。
本書所介紹的九大演算法是:搜尋引擎的索引(search engine indexing)、網頁排序(page rank)、公鑰加密(public-key cryptography)、錯誤更正碼(error-correcting codes)、模式辨識(pattern recognition,如手寫辨識、聲音辨識、人臉辨識等等)、資料壓縮(data compression)、資料庫(databases)、數位簽章(digital signature),以及一種如果存在的話將會很了不起的偉大演算法,並探討電腦能力的極限。
作者將我們日常生活會用到的電腦功能背後的道理,以淺顯易懂的方式介紹,不具備資訊科學的背景也可以了解。而且令人驚喜的是,每一種演算法,都是一個解決問題的創意與線索,也讓我們得以一窺近代數學家、資訊科學家的努力探索成果。面對越來越科技化的現代生活與職場挑戰,這些基本原理和概念值得我們去了解、吸收,為未來世界做好準備。
【媒體好評】
「這是一本很容易讀的書,介紹了一些很重要的演算法。最重要的是,這本書傳達了一種神奇——不光是指科技的成就,而是使得電腦發揮神奇功能的美麗科學。」
——Andreas Trabesinger,《自然物理學》(Nature Physics)
「這本書寫得非常好……風格相當平易近人,適合廣大讀者閱讀。」
——John Gilbey,《泰晤士報高等教育專刊》(Times Higher Education)
「作者讓讀者有一種發動機的感覺,這台發動機為網路世界提供動力……本書讓讀者體會真實世界,開始看到這些演算法在你我周遭活跳跳。」
——Kevin Slavin,《新科學家》(New Scientist)
「成功地把電腦科學呈現給廣大群眾。」
——Ernest Davis,《工業與應用數學學會通訊》(SIAM News)
「作者讓大家稍稍體會到,我們電腦科學家們之所以對演算法如此興奮的原因——因為演算法的功用,還有它們的美與優雅。」
——Paul Curzon,《科學》(Science)
目錄
目 次
推薦序 當演算法改變世界,認識演算法就是義務 / 鄭國威
前言
第1章 引言:讓今日電腦威力無窮的神奇概念
演算法:天才就在彈指間
偉大演算法的條件是什麼?
這些偉大的演算法為什麼重要?
第2章 搜尋引擎的索引:配對與排序
AltaVista:第一個網路規模的配對演算法
古早時代的陽春式索引
文字─位置技法
排序與相鄰
元詞技法
光是標註索引和配對技法還不夠
第3章 網頁排序:讓谷歌起飛的技術
超連結技法
權威性技法
隨機漫遊技法
網頁排序的實作
第4章 公鑰加密:用明信片寄送祕密
用共同的祕密來加密
設定一個公開的共同祕密
實務上的公鑰加密
第5章 錯誤更正碼:錯誤可以自己修正!
偵錯與改正的必要性
重複的技法
冗餘技法
校驗技法
定點目標技法
真實世界中的糾錯與偵錯
第6章 模式辨識:從經驗中學習
問題是什麼?
最近鄰居技法
二十個問題技法:決策樹
神經網路
模式辨識:過去、現在、未來
第7章 資料壓縮:白吃的午餐r
無損失的壓縮:終極的白吃午餐r
有損失的壓縮:不是白吃的午餐,但很划算
壓縮演算法的由來
第8章 資料庫:追求一致性
交易與待辦事項清單技法
複製資料庫所用的「準備然後承諾技法」
關聯式資料庫與虛擬表格技法
資料庫的人性面
第9章 數位簽章:這軟體到底是誰寫的?
數位簽章究竟用來做什麼?
書面簽字
上鎖的簽字
利用乘法鎖來簽字
利用指數型鎖來簽字
數位簽章的實務
解決矛盾
第10章 什麼是可計算的?
程式錯誤、毀壞和軟體的可靠度
反證法
用於分析其他程式的程式
有些程式不可能存在
尋找當機的程式不可能存在
電腦的極限給我們的啟示
第11章 結論:未來會如何呢?
頗具潛力的演算法
偉大的演算法可能失去光彩嗎?
我們學到了什麼?
旅程的結束
資料來源與延伸閱讀
序跋
前言
◎文畢夏普Chris Bishop(微軟劍橋研究中心卓越科學家、英國皇家學院副院長、愛丁堡大學資訊科學教授)
電腦運算(computing)正在改變我們的社會,影響之深一如物理學和化學在過去兩百年為人類帶來的改變。數位科技幾乎全面影響你我的生活乃至於掀起革命,有鑑於電腦運算對現代社會的重要性,然而人們對造就這一切事物的基本概念所知卻如此有限,就顯得有些矛盾了。電腦科學的核心正是在研究這些概念,而這本約翰.麥考米克(John MacCormick)的新書,就是將這些概念傳達給一般讀者的少數書籍之一。
一般人對於電腦科學做為一門學科的體認相對欠缺,理由之一是在高中階段很少教導這些東西。物理和化學的入門課通常是必修,然而通常要到了大專、大學階段,才真正有電腦科學這門課。此外學校教的電腦運算或資訊與通信技術(Information and communication technology,簡稱ICT),通常只是使用套裝軟體的技術訓練,也難怪學生會覺得乏味。即使學生很自然地對於電腦技術應用在娛樂和通訊方面感到興趣,但卻因為印象中這些技術的創造缺乏學術的深度,使得他們的興趣沒有進一步發展。或許這就是過去十年來,美國研讀電腦科學的大學生人數減少了50%的原因。基於數位科技對現代社會的關鍵重要性,現在正是讓人們對電腦科學的奧祕重燃起興趣的最佳時機。
2008年,我有幸被選中在第180屆英國皇家科學院聖誕講座(Royal Institution Christmas Lectures)上台報告,這個活動是由偉大科學家法拉第(Michael Faraday)於1826年所發起。2008年的演講首度以電腦科學為主題,我在準備時花了很多時間思索該如何向普羅大眾介紹電腦科學,結果發現資源很少,幾乎沒有科普書能滿足這樣的需要,也因此這本書特別令人期待。
作者將複雜的電腦科學觀念很完美地傳達給讀者大眾,其中一些觀念的美與優雅,本身就值得大眾的關注。舉個例子:過去幾十年來,在公開管道上進行安全通訊一直是個棘手問題,直到人們想出了如何在網路上安全地傳送機密資訊(例如信用卡卡號),才造就了電子商務爆炸性的成長。在本書中,作者是以比喻的方式來說明這些優雅的解決方案的來龍去脈,讀者不須具備電腦科學知識就可以理解。諸如此類的優點,使本書成為不可多得的科普書籍,我極力推薦。
內文試閱
引言:讓今日電腦威力無窮的神奇概念
二十一世紀的人類享受科技的驚人進步,像是目前威力最強的機器群組或最新最時尚的手持式裝置,然而人們在使用電子運算裝置的同時,也要仰賴二十世紀所發現的電腦科學基礎概念。不妨想一下:
你是否曾經在數十億份資料中搜尋,然後挑出兩三份最合乎你需求的資料?
你是否儲存或傳輸了數百萬筆資訊,沒有一次發生錯誤,即使所有的電子器材都遭到電磁干擾?
你是否成功地完成一筆線上交易,即使還有數千個人也同時把資料敲進同一台伺服器?
你是否在電纜線上安全地傳輸機密資訊(如信用卡卡號),哪怕有幾十台電腦可能透過纜線窺伺你的一舉一動?
你是否運用神奇的壓縮技術,把一張數MB大的照片壓縮成方便電郵傳送的大小?
最後,你是否利用手持裝置那小小鍵盤上,針對你輸入的字詞進行自動偵錯的人工智慧而不自知?
這些了不起的功能仰賴以上所述的重要發現,大部分的電腦使用者每天多次運用這些巧妙的概念,卻往往渾然不覺。這本書的目的,就是盡量把日常使用到的偉大電腦概念解釋給最廣大的讀者,而不預設讀者具備任何電腦科學的知識。
演算法
目前為止我談論的是電腦科學的偉大「概念」,其實電腦科學家把許多重要概念描述成一個個「演算法」(algorithm)。概念和演算法之間有什麼不同?演算法究竟是什麼?
簡單來說,演算法好比一個「精確的食譜」,把解決問題的確切步驟解釋得一清二楚,最好的例子是我們小時候在學校學過的,把兩個很大的數相加的演算法,如圖1-1。這個演算法包含一連串步驟:首先把兩個數的個位數相加,寫下結果的個位數,把結果的十位數放到它左邊那個欄位;第二步,將十位數的數字相加,再加上前一欄位的進位數字……就這麼加下去。
演算法的各步驟具有機械式的特質,每個步驟必須絕對精確,不需要靠人類的直覺或猜測,這也是演算法的關鍵特點,如此一來每個純機械式的步驟就可以被編寫成程式之後輸入電腦。
演算法的另一個重要特點,就是無論輸入什麼都能給出正確答案。加法演算法就具備這項特質,換言之無論你想把哪兩個數相加,演算法都會產生正確的答案。舉例來說,儘管很花時間,但你一定可以利用這個演算法,把兩個一千位數的數相加。
演算法是精確的機械式食譜,或許這個定義會讓你好奇,究竟食譜要多精確?哪些基礎運算是被允許的?就以相加的演算法為例,可不可以光是說「把兩個數加起來」,還是必須明確列出一整組單一數字相加的表格?像這類細節或許有點做作,但這些問題其實正是電腦科學的核心問題,而且與哲學、物理學、神經科學和基因遺傳學相關。演算法究竟是什麼,這個深奧的問題終歸所謂「丘池─圖靈論點」(Church-Turing thesis),第十章將再回到這個議題,探討電算理論的限制。目前先把演算法視為「非常精確的食譜」就行了。
本書要談的演算法
接著來看我選出來的演算法。搜尋引擎的無遠弗屆的影響力,證明了演算法技術可以影響所有電腦使用者,因此我納入一些與網路搜尋相關的核心演算法。第二章敘述搜尋引擎如何利用標註索引的方式找到符合查詢條件的文件,第三章解釋何謂網頁排序(PageRank),這是谷歌為了確保最相關的文件被列在搜尋結果的最頂端,所使用演算法的原始版本。
大部分的人多少會注意到,搜尋引擎是利用一些深入的電腦科學觀念來提供有用的答案。但是,有些偉大的演算法卻往往在電腦使用者渾然不覺之際被啟動,如第四章的公鑰加密。每當你進入一個安全的網站(網址是以https開頭,而不是http),就是在使用所謂密碼交換(key exchange)的公鑰加密來保護傳輸的資料,第四章將解釋這種密碼交換的機制。
第五章的錯誤更正碼,也是我們一直在使用卻沒有察覺的演算法,事實上錯誤更正碼可說是至今人們最頻繁使用的偉大概念,電腦無須借助備份或重新傳輸,就能查知並更正被儲存或傳輸資料的錯誤。錯誤更正碼無所不在,包括所有硬碟機、許多網路傳輸、CD和DVD,甚至在某些電腦的記憶體裏──只是錯誤更正碼運作得太完美,以至於我們根本沒有意識到它的存在。
第六章探討模式辨識的演算法,可說是被我夾帶進入電腦科學的偉大概念清單,因為它並非電腦使用大眾每天使用,因此不符第一項標準。電腦透過此種技術來辨識手寫、口說和人臉等具高度變異性的資訊。事實上,在21世紀的第一個10年間,日常電算功能大多沒有使用這項技術,但在我撰寫本書的2011年,模式辨識的重要性驟增,行動裝置螢幕上的小型鍵盤需要自動更正、平板裝置必須辨識手寫輸入,且愈來愈多這類裝置(特別是智慧型手機)採用聲控,有些網站甚至用模式辨識來判斷該把什麼類型的廣告呈現給使用者。我個人偏愛模式辨識,因為那是我的專業研究領域,因此第六章將說明最近鄰居分類法(nearest-neighbor classifier)、決策樹(decision tree)和神經網路(neural networks)等三種最有趣且最成功的模式辨識技術。
第七章的壓縮演算法來自另一組偉大的發想,讓電腦變得更聰明有用。電腦使用者有時為了節省硬碟空間或縮小照片所佔的記憶容量以便透過電郵傳送而直接應用壓縮,其實壓縮功能在私底下更常被使用,我們沒有注意到上傳和下載的資料可能經過壓縮以節省頻寬,資料中心往往壓縮顧客資料以節省成本,至於電郵提供者容許你使用的5GB空間,實際占用的儲存空間說不定遠小於5GB!
第八章是資料庫的一些基本演算法,主要是探討如何達到一致性(consistency)──資料庫中資料之間的關係絕不會彼此矛盾。少了這些精妙的技術,你我的網路生活(包括網路購物、在臉書之類社交網站上的互動)將毀在電腦層出不窮的錯誤中。這一章將解釋「一致性」的問題,電腦科學家如何解決它,而不犧牲網路系統帶來的無比效率。
第九章來到電腦科學理論公認的閃亮巨星──數位簽章。乍看之下,用數位方式在電子文件上「簽章」似乎不可能,你當然會想,所有這類的簽章一定包含了數位資訊,因此凡是想偽造簽章的人都可以輕易拷貝。解決這種兩難局面正是電腦科學最了不起的成就之一。
第十章的口味大不相同,不介紹已經存在的偉大演算法,而是看看如果存在的話會很了不起的演算法。我們將會發現,這麼了不起的演算法竟然不可能存在,這也證實電腦解決問題的能力受到某些絕對的限制,我們也將簡短探討這在哲學和生物學上的含義。
最後在結論中,我們從各個偉大的演算法歸納出共同理路,花點時間推測:未來還會有更多偉大的演算法被發明出來嗎?
我還應該談談這本書的書名。這無疑是革命性的一本書,但難道只有這九個演算法是重要的嗎?這倒是見仁見智,而且要看哪些可以被歸為一種演算法。除了引言和結論之外,這本書共有九章,每一章都探討一種為不同的電算任務帶來革命的演算法,例如加密、壓縮、或模式辨識等等。因此書名的「九大演算法」,其實是指解決這九個電算任務的九種演算法。
關於公鑰加密(public key cryptography)的演算法
人喜歡八卦,喜歡祕密。加密的目的是為了傳遞祕密,因此每個人都是天生的加密高手──人能夠比電腦更輕易地祕密溝通,如果你想告訴朋友一個祕密,只要在對方的耳朵旁講悄悄話就行了,電腦可就沒那麼容易辦到,電腦沒辦法把信用卡卡號「輕聲」說給另一台電腦聽,如果電腦和網際網路連線,就更加無從控制信用卡卡號會被傳到哪裏、被哪幾台電腦窺知。本章將探索電腦如何利用公鑰加密(public key cryptography)來克服這個問題,而這也是電腦科學至今最聰明且最具影響力的概念。
現在你或許想問,本章的副標題為何是「用明信片寄送祕密」,答案就在圖4-1。我們把公鑰加密比喻成用明信片溝通,現實生活中,如果你想寄機密文件給某人,你當然會把文件妥善密封在信封裏寄出,雖無法保證天衣無縫,但畢竟不失為穩妥的做法。把機密訊息寫在明信片上寄出顯然無法保密,因為凡是接觸得到明信片的人(例如郵務員)都會看到明信片上的訊息。
以上正是電腦在網際網路上進行祕密溝通時遇到的問題。由於網路上的任何訊息通常都會經過許多「路由器」(routers),凡是能進入路由器的人(包括惡意竊聽者)都能一窺訊息內容,因此從你的電腦出去的每一筆資料進入網路後,就如同寫在明信片上一樣!
或許你已經替明信片問題想到快速的解決之道。何不用密碼在訊息上加密後,再寫在明信片上?如果你認識收件人,這麼做是可行的,因為你們過去可能已經針對密碼達成共識,但真正的問題在於你寄明信片給不認識的人時,如果你在這張明信片上使用密碼,那麼郵務員將無從知道你的訊息,但收件人也看不懂!公鑰加密真正厲害的地方是,你使用只有收件人能破解的密碼,儘管你們根本沒機會針對使用的密碼暗中達成共識。
電腦在面對不認識的收件人時也面臨同樣的溝通問題。例如你第一次用信用卡在亞馬遜網站買東西,於是電腦必須將你的信用卡卡號傳給亞馬遜的伺服器,但是你的電腦從沒和亞馬遜的伺服器傳輸過訊息,因此這兩台電腦過去沒有機會針對密碼達成共識,而它們試圖達成的任何共識,都可以被網路上它們之間所有的路由器觀察到。
現在回到明信片的比喻。我承認這狀況聽起來有點矛盾,收件者看到的資訊與郵務員看到的資訊一模一樣,但收件者能夠將訊息解密,郵務員卻不能。公鑰加密將為這個矛盾的情況提供解答,接下來進一步說明。
用共同的祕密來加密
首先是個簡單的例子,也就是在一間房間裏進行口語溝通。你跟你的朋友阿諾和你的死對頭伊芙在同一個房間裏,你想偷偷傳訊息給阿諾,又不希望讓伊芙知道訊息的內容,或許這訊息是信用卡卡號,但為了簡化起見,就假設是1到9之間的一個數字吧。此外你只可以用大聲說出來的方式跟阿諾溝通,而這麼一來又會被伊芙聽到,輕聲細語或遞紙條等小聰明的舉動一律不准。
假設你想傳的信用卡卡號是7,其中一種傳遞方式,就是先試著想一個阿諾知道但伊芙不知道的數字,例如你和阿諾小時候住在同一條街上,你們經常在你家的前院玩耍,地址是快樂街322號。又假設伊芙小時候並不認識你,特別是她不知道你和阿諾以前玩耍的這個地方的地址,於是你可以跟阿諾說:「嘿阿諾,我們小時候在我快樂街的家玩,你還記得那裏的門牌號碼嗎?如果你把門牌號碼加上信用卡卡號,結果是329。」
只要阿諾記得正確的門牌號碼,就可以將你告訴他的329減去門牌號碼,得出信用卡卡號。他將329減去322得出7,也就是你想傳給他的信用卡卡號。另一方面,儘管伊芙聽見你和阿諾說的每一個字,但還是無法知道信用卡卡號。圖4-2說明整個過程。
這個方法有用,是因為你和阿諾之間存在著電腦科學家所說的「共同祕密」(shared secret),也就是322。因為你們知道這個數字但伊芙不知道,於是就可以利用這個共同祕密來傳遞任何想傳遞的數字,只要加上這個數字再把總數說出來,讓對方減去共同的祕密即可。伊芙聽到總數卻不能怎麼樣,因為她不知道該減去什麼數字。
信不信由你,只要懂得簡單的「加法技法」,將共同的祕密數字加在像信用卡卡號這種私人訊息上,你就知道網際網路上絕大多數的加密是怎麼運作的!電腦一直在使用這種技法,但是為了確保萬無一失,還有幾個細節要注意。
首先,電腦使用的共同祕密必須比門牌號碼322長很多,否則偷聽到對話的人就可以試遍所有可能性。例如,假設我們用加法技法將三位數的門牌號碼與16碼的信用卡卡號相加,由於三位數的門牌號碼共有999種可能性,因此偷聽到我們對話的伊芙就可以列出相對的999個信用卡卡號,而其中一個必定是你的信用卡卡號。至於電腦幾乎在瞬間就可以試遍999個信用卡卡號,所以共同祕密必須要比三位數再多很多位數才有用。
事實上,當你聽到某個位元數的加密法,如128位元加密(128-bit encryption),其實指的就是共同祕密的長度。共同祕密通常被稱為「公鑰」,因為它可以被用來解鎖或解密訊息。如果你算出公鑰中30%的位元數,就會知道公鑰大約有幾位數字。由於128的30%約為38,所以128位元加密的公鑰是一個38位數的數字。一個38位數的數字比十億的4次方還大,一般電腦要花幾十億年才能試遍所有的可能性,因此38位數的共同祕密被認為非常安全。(作者注:如果你了解電腦的數字系統,此處的38位數是十進位數字而非二進位數字〔位元〕。若是你懂得對數,從位元轉成十進位數字的30%的轉換比率,是來自log102 ≈ 0.3。)
還有一個小問題,導致簡單版本的加法技法無法在真實生活暢行無阻,那就是加法得出的結果可以用統計分析,換言之只要分析大量經過加密的訊息就能破解公鑰。因此,現代的加密技術「分塊加密」(block ciphers)是加法技法的一種變化版。
它是這麼做的。首先,長訊息被細分成固定長短的「小塊」,每一塊通常是10到15個字元。第二,不是光把小塊訊息加上公鑰,而是根據一組固定的規則將每塊訊息經過多次轉換,這套規則與加法類似,但卻是以更難被破解的方式將訊息與公鑰混合,例如規則可能是:「將公鑰的前半段加到小塊訊息的後半段,將結果反轉再將公鑰的後半段加到小塊訊息的後面。」真正的規則要比這複雜多了。現代分塊加密通常經過十回合以上類似的加加減減,換言之這些加減運算重複被使用。經過夠多的回合後,原始訊息已經「面目全非」而禁得起用統計學進行攻擊,但是只要是知道公鑰的人就能倒推以上運算,得到解密後的原始訊息。
關於網頁排序(PageRank)的演算法
「星際大戰」裏的電腦好像很遜,隨便問一個問題它都得想好久。我認為我們可以做得更好。──佩吉(谷歌共同創辦人)
PageRank是個雙關語,它既是一種替網頁排序的演算法,也是主要發明人佩吉(Page)的排序演算法。1998年佩吉和布林在一個學術會議上發表名為〈大規模超文本網頁搜尋引擎之剖析〉(The Anatomy of a Large-Scale Hypertextual Web Search Engine)的論文,而將這個演算法公諸於世。這篇論文如其標題所示,不光是說明網頁排序而已,而是完整敘述了1998年時的谷歌系統。然而藏在大量技術細節當中的,是21世紀時將成為演算法之王的網頁排序演算法。本章將探討這個演算法如何以及為何能在稻草堆中撈針,總是把最相關的結果呈現給使用者。
超連結技法
超連結(hyperlink)是網頁上的「片語」,只要用滑鼠點它就會帶你到另一個網頁。大部分的網頁瀏覽器會用藍色底線標示來凸顯。
要了解網頁排序,第一步是了解「超連結技法」這個簡單概念。假設你想知道如何炒蛋,於是上網搜尋。真正上網搜尋炒蛋會出現上百萬筆符合條件的資料,但為了簡化起見,姑且想像結果只有兩個網頁,一個叫做「爾尼的炒蛋食譜」,另一個是「伯特的炒蛋食譜」。圖3-1呈現這兩個網頁,以及其他有超連結到這兩個網頁的網頁。再次為了簡化起見,想像整個網路上只有四個網頁連結到這兩種炒蛋食譜,超連結以畫線的內文呈現,箭頭表明所連結到的網頁。
問題是,伯特和爾尼的炒蛋食譜網頁,究竟誰該排在前面?對人類來說,直接去閱讀這兩個食譜的頁面來做判斷並不難──可惜,電腦無法輕易了解某個網頁真正的意思,因此搜尋引擎無法檢視這四個連結到食譜的網頁,來評估每個食譜受好評的狀況。幸好電腦很會計數,所以一個簡單的方法是去計算每個食譜分別有幾個外來的連結──在此例中爾尼有一頁、伯特三頁──然後根據這個數量來排序。結果發現,在沒有其他資訊的情況下,一個網頁所擁有的外來連結數,可能足以成為該網頁實用性與權威性的指標,在此伯特的網頁得到三分,爾尼得到一分,於是搜尋引擎在呈現結果時,會將伯特的網頁排在爾尼前面。
權威性技法
或許你想知道,為什麼所有外來連結應該被一視同仁,畢竟專家推薦不是比菜鳥推薦更有價值嗎?為了瞭解細節,我們繼續以上述炒蛋的網頁為例,只是用另一組來自外部的連結。圖3-2說明新的情況,伯特和爾尼各自都只有一個外來連結,只是爾尼的連結來自我(作者)的首頁,而伯特的連結則來自知名的主廚艾莉絲.沃特斯(Alice Waters)。
在沒有其他資訊的情況下,你對誰的食譜比較感興趣?名廚推薦的食譜顯然比電腦書作者(我)推薦的食譜要來得好,基本原理是我們所謂的權威性技法(authority trick),也就是來自高權威性網頁的連結,應該比低權威性網頁的連結獲得較高的排序。
這個原則看來合情合理,但以目前這種形式對搜尋引擎並沒有用處,電腦要如何自動判斷沃特斯在炒蛋方面比我更具權威性?將超連結技法結合權威性技法或許有幫助。所有網頁一開始的權威分數都是1分,但如果某個網頁有幾個外來連結,它的權威性就等於這些外來連結的權威分數加總,換言之,如果X和Y網頁連結到Z,則Z的權威分數就等於X和Y的權威分數的和。
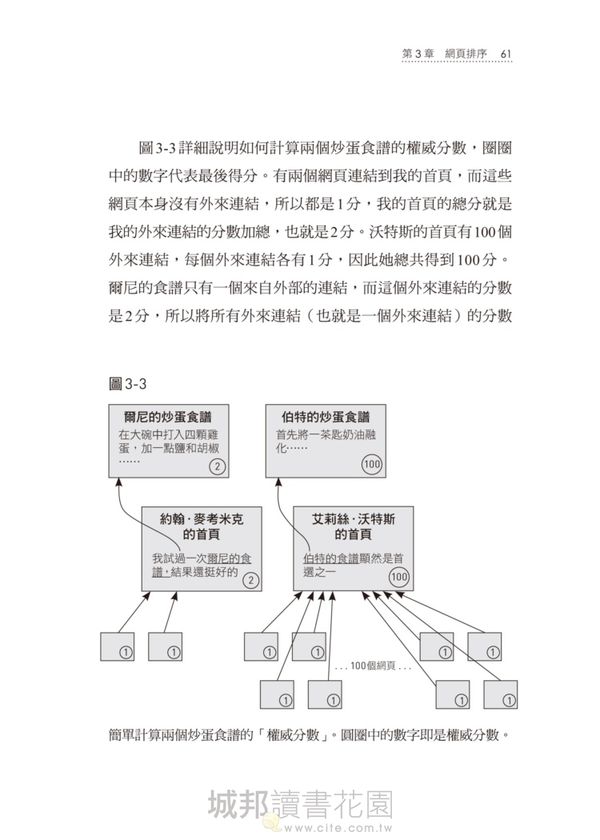
圖3-3詳細說明如何計算兩個炒蛋食譜的權威分數,圈圈中的數字代表最後得分。有兩個網頁連結到我的首頁,而這些網頁本身沒有外來連結,所以都是1分,我的首頁的總分就是我的外來連結的分數加總,也就是2分。沃特斯的首頁有100個外來連結,每個外來連結各有1分,因此她總共得到100分。爾尼的食譜只有一個來自外部的連結,而這個外來連結的分數是2分,所以將所有外來連結(也就是一個外來連結)的分數加總,爾尼獲得2分;伯特的食譜也只有一個得分為100分的外來連結,於是伯特的最後計分為100分。由於100大於2,因此伯特的網頁就排在爾尼之前。
隨機漫遊技法
看來這個策略能讓電腦自動計算權威分數又無需真正了解網頁內容,但不幸的是,這個方法可能有個大問題。超連結很可能形成電腦科學家所謂的「兜圈子」(cycle),如果你藉由點擊一連串超連結能夠回到原點,這時的你就是在「兜圈子」。
在實務上也有一個問題是,人們可能濫用超連結技法而刻意拉抬自己網頁的排名。假設你經營一個叫做BooksBooksBooks.com的賣書網站,利用自動技術不難製造出大量(例如一萬個)網頁,而且每個網頁都連結到BooksBooksBooks.com。因此如果搜尋引擎用此處描述的方法計算「網頁排序」的權威,該網站恐怕會比其他網路書店的分數高好幾千倍,而高排名也帶來更多業績。
幸好我們可以利用「隨機漫遊技法」(random surfer trick)來解決這個問題。請留意,隨機漫遊技法一開始的描述與超連結與權威性技法並無相似之處,等探討過隨機漫遊技法的基本機制後,會分析它不可思議的特質,看它如何結合超連結與權威性技法的優點,即使在兜圈子的情況下依舊能發揮應有的功能。
首先,想像有人正隨機地在網路上漫遊,這位漫遊者從全球資訊網上隨機挑選一個網頁開始,接著檢視這個網頁上所有的超連結,隨機挑選其中一個按下滑鼠。接著,他檢視這個新網頁並隨機選擇一個超連結按下滑鼠……這個過程繼續下去,每個新網頁都是在前一個網頁隨機點選一個超連結而產生的。圖3-5當中,想像整個全球資訊網上只有十六個網頁,框框代表網頁,箭頭代表網頁之間的超連結。
整個過程有一個特點,也就是當漫遊者來到一個網頁時,他不點選其中一個超連結而選擇重新開始的機率是固定的(假設是15%),這時他會從網路隨機挑選另一個網頁,重新開始整個過程。可以這麼想像:網路漫遊者有15%的機率會對任何一個網頁感到無趣,因此重新開始,走另一趟新的連結。
(順帶一提,本章所有隨機漫遊的例子是用15%的重新開始機率。而谷歌創辦人佩吉和布林在最初的論文中,就是用15%的重新開始機率來說明他們的搜尋引擎原型。)
隨機漫遊者模型涵蓋了超連結技法和權威性技法,一併考慮每個網頁外來連結的質與量。隨機漫遊技法的美妙之處在於,不論超連結是否出現兜圈子的情況都一樣管用。
延伸內容
當演算法改變世界,認識演算法就是義務
◎文/鄭國威(PanSci泛科學總編輯)
看完本書書稿,回頭繼續盯著電腦工作的我,有點感動,彷彿跟網路世界交上了心。
科普書的市場準則:出現的算式越多,賣得越差。曾經聽一位出版社編輯說,即使是在書名上出現「E=mc2」,都會讓他們猶豫再三,深怕影響銷量,這也難怪針對電腦科學或演算法的科普書那麼的少。即便我們的世界已經被電腦科學所顛覆,絕大多數的人,包括我在內,都只是傻傻地看著奇蹟變成慣習。
《改變世界的九大演算法》是本我願意大力讚許跟推薦的好書,不僅因為這本書勇於碰觸科普書出版的禁忌,而是因為本書作者,美國迪金森學院數學暨電腦科學系教授約翰.麥考米克(John MacCormick)俐落的文筆跟清晰的鋪陳,足以抹消非專業人士對演算法的恐懼。
搜尋引擎到底是如何在百億個網頁之中,於零點幾秒之內找到我們想要的那個連結?讓數十億人感到滿意的網頁排序是如何實現的?如何在網路上傳輸隱私資訊,而不被中間無數節點看得一清二楚?如何驗證收到的資料是正確,無篡改的版本?人工智慧的基本原理是什麼?…… 如同作者所說,看完本書並不會讓你我可以即刻動手寫程式,變成演算法大師,但了解其運作原理,足以讓人感到任督二脈暢通,擁有了練內力的根基。
作者善於用簡單的小案例開始,一層層地將演算法的精神跟實際應用堆疊而上,讓我們從邏輯上去了解演算法的設計因由,至於繁複的計算過程在本書其實並非主角,除了幾個掰掰手指就能算出的範例外,作者並未給讀者太多負擔,因為在真實情況下,要展現演算法的能耐,也只能交由電腦去算。只要邏輯通了,演算法的設計美感就自然浮現,而這就是作者每一章節由淺入深,幾乎可說是循循善誘的寫作想要帶領我們進入的境界。
近來最熱門的科技產業關鍵詞「大數據」,讓產官學無不趨之若鶩,但大數據跟青少年的性經驗一樣:每個人都在談,每個人都宣稱自己做了,然而真正讓數據展現出價值的並非空談,而是演算法。從股市到戰爭,從自動交易到自動使用武力,背後都是演算法,而儘管實際做法不同,但看完本書,你都能更加理解演算法何以改變世界,也比較能理性地看待許多吹得上天下地的大數據忽悠文。
從另一方面來看,演算法本身即是戰場。無數網路高手抱持著挑戰或是為惡的心態,試圖打穿演算法之牆(或是悄悄繞過),有趣的是,台灣正是核心戰場之一。「誰說台灣是個沒有天然資源的國家?台灣最大的天然資源就是病毒樣本」這句話來自於一位知名台灣駭客 Birdman。台灣面對的入侵跟資安事件多不勝數,在世界上僅次於美國,是病毒(惡意程式)樣本數量最多的地方,既然如此,那麼對我們來說,多去認識電腦科學與演算法,就更是一種義務了。
作者資料
約翰.麥考米克(John MacCormick)
他是資訊科學領域傑出的研究學者與教授。他在牛津大學取得電腦視像(computer vision)博士學位,曾經在惠普(HP)與微軟(Microsoft)的研究實驗室工作。目前於賓州的狄金森學院(Dickinson College)擔任資訊科學教授。












注意事項
- 若有任何購書問題,請參考 FAQ