









- 庫存 = 5
 放入購物車
放入購物車 直接結帳
直接結帳 放入下次購買清單
放入下次購買清單-




統計的藝術:如何從數據中了解事實,掌握世界
- 作者:大衛.史匹格哈特(David Spiegelhalter)
- 出版社:經濟新潮社
- 出版日期:2021-08-05
- 定價:580元
- 優惠價:79折 458元
- 優惠截止日:2026年3月25日止
-
書虫VIP價:458元,贈紅利22點
活動贈點另計
可免費兌換好書 - 書虫VIP紅利價:435元
- (更多VIP好康)
-
購買電子書,由此去!
分類排行
-
模範領導【增訂第六版】:從自我領導開始,掌握五大實務要領、十大承諾,讓團隊成員願意主動成就非常之事

-
股市宗師杜金龍的獨門選股術

-
簡報的技術【限量作者親筆簽名版】

-
阿甘節稅法:全方位理財第三堂課,讓你隱形加薪,退休金翻倍

-
行銷前必修的購物心理學:徹底推翻被誤解的消費行為,揭開商品大賣的祕密【十週年暢銷增訂版】

-
原子習慣WORKBOOK【官方版‧附練習別冊】

-
財富自由心理學:療癒金錢焦慮,修練致富心態

-
台灣AI大未來:解析最新的AI趨勢、台灣情勢、企業布局與個人發展

-
持續買進:資料科學家的投資終極解答,存錢及致富的實證方法

-
不逃避的領導力:美國最受歡迎商業講師親授,打破管理刻板思維、激發團隊潛能的動機革命

最近瀏覽商品

內容簡介
#英國Amazon網站1,700多位讀者,四顆半星強力推薦!
#英國劍橋大學統計學權威,帶給你最有趣、最有價值的統計思維
統計學如何幫助我們了解世界?
當資料不完美,我們能做出可靠的結論嗎?
在資料科學的時代,統計學如何與時俱進?
當疫情來襲,我們如何自己做好觀念上的準備?
在許多領域中,統計學都是必備的技能;在人工智慧的時代,統計在商務上的運用也越來越重要。
但是一般的統計學內容,即使有嚴謹的定義和推論,卻總是感覺和現實世界隔了一層,不知如何運用,也很難理解它。
許多人在學校或許讀過一點統計學,大概知道隨機變數、標準差、平均數、中位數的意義,但到底該怎麼用?如何應用到現實世界的問題呢?
然而,這本書不同,它帶你用一種全新的方式來了解統計學。它從一些現實世界的問題開始,例如:
地球上有多少棵樹?
培根三明治的致癌風險有多高?
我們能夠相信群眾智慧嗎?
如何衡量藥物的有效性?
英國人的一生中有多少個性伴侶?
病人多的醫院,存活率比較高嗎?
半個世紀以來,全球人口成長的型態如何?
為什麼老男人的耳朵都很大?
配上生動有趣的圖表,讓讀者更容易進入,也展示了將資料化為圖表的強大力量與陷阱,以及溝通、道德問題在統計上的重要性。
本書的作者,英國劍橋大學的統計學權威大衛.史匹格哈特(David Spiegelhalter),十分擅長利用統計學說故事,而且概念清晰,盡量不談技術性的細節,他將統計學當中極易混淆的觀念,例如平均數和中位數、標準差、隨機試驗、母體、迴歸模型、隨機變數、預測區間和信賴區間、假說檢定(偽陽性、偽陰性問題)、P值、貝氏方法等等,以生動的實例和圖表,一步步清楚說明。
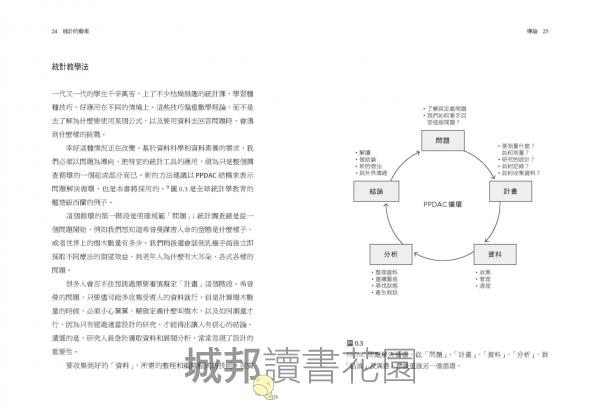
這本書也強調,統計學應該要教「PPDAC的問題解決循環」,即「問題─計畫─資料─分析─結論及溝通」。先從定義問題開始,再制定計畫,包括要測量什麼、如何測量,然後要收集資料,根據計畫展開統計分析,最後決定適當的結論,並清晰準確地溝通給外界知道。
正如一句名言所說的:「所有的模型都是錯的,但有些模型有用。」雖然統計的模型並不完美,但是如果我們想要得出一些結論,在數據的洪流當中增進對這個世界的理解,這些模型還是有幫助的。
作者強調,統計學對於已知的事實作匯總,對於未知的不確定性作出估計,最後應該以謙遜的態度,說明我們能從資料中得到什麼,不能得到什麼。要抱持小心審慎的態度,包括對於各種媒體報導的數據和說法,進行審慎的判斷。
本書對於統計學及其廣泛的應用作了深入解讀,讀這本書,你會對統計學產生興趣,知道統計學在做什麼,以及如何應用到實際問題上,還有統計學這門學問的美妙精髓與限制,這些將是讀者珍貴的收穫。
目錄
致謝 11
導論 13
我們為什麼需要統計學/將世界化為資料/統計教學法/關於本書
第1章 用百分比了解情況:類別資料和百分率 31
次數和百分比的溝通/類別變數/比較一對百分比
第2章 滙總和溝通數字 51
描述資料分布的廣度/描述數字群之間的差異/描述變數之間的關係/描述趨勢/溝通/使用統計量說故事
第3章 為什麼我們還是要查看資料?母體與測量值 85
從資料中找答案——「歸納推論」的過程/當我們有了全部的資料/「鐘形曲線」/母體是什麼?
第4章 什麼因造成什麼果?隨機試驗 105
「相關不表示有因果關係」/到底什麼是「因果關係」?/不能隨機化時,怎麼辦?/當我們觀測到有關聯性,能夠怎麼做?/我們能否從觀測性資料得出因果關係的結論?
第5章 利用迴歸將關係建模 129
迴歸線就是模型/處理一個以上的解釋變數/不同種類的反應變數/超越基本的迴歸建模
第6章 演算法、分析和預測 149
尋找型態/分類和預測/分類樹/評估演算法的表現/機率「準確度」的組合測量值/過度配適/迴歸模型/更複雜的技術/演算法面對的挑戰/人工智慧
第7章 對於正在發生的事,我們能有多確定?估計和區間 191
性伴侶人數/拔靴法
第8章 機率:不確定性和變異性的語言 207
一點都不難的機率法則/條件機率—當機率取決於其他的事件/「機率」到底是什麼?/如果我們觀測一切,機率從何處介入?
第9章 結合機率與統計 229
中央極限定理/這個理論如何幫助我們確定估計值的準確度?/計算信賴區間/調查的誤差範圍/我們應該相信誤差範圍嗎?/當我們擁有所有的資料,會發生什麼事?
第10章 回答問題和宣稱發現:假說檢定 251
什麼是「假說」?/為什麼我們需要對虛無假說做正式的檢定?/統計顯著性/運用機率論/執行許多次顯著性檢定的危險/內曼—皮爾遜理論
第11章 用貝氏方法,從經驗中找答案 299
貝氏方法是什麼?/勝率和概似比/概似比和法醫學/貝氏統計推論/意識形態之爭
第12章 事情怎麼會出錯? 331
「可再現性危機」/蓄意詐欺/「有問題的研究實務」/研究人員實際上做了多少有問題的研究實務?/溝通失敗/文獻會出什麼問題?/新聞辦公室/媒體
第13章 如何把統計做得更好 351
改善產生的結果/改進溝通/協助找出不良的做法/發表偏差/評估一項統計宣稱或報導/面對根據統計證據發表的聲明,要問的十個問題/資料倫理/良好的統計科學實例
第14章 結論 367
詞彙解釋 369
註釋 397
內文試閱
導論
數字不會自己說話。是我們為它們說話,給它們意義。
——奈特.席佛(Nate Silver),《精準預測:如何從巨量雜訊中,看出重要的訊息?》(The Signal and the Noise)
我們為什麼需要統計學
哈羅德.希普曼(Harold Shipman)是英國被判有罪,殺人最多的兇手,但不符合連環殺手的原型特徵。家庭醫生希普曼在曼徹斯特(Manchester)郊區執業,待人隨和親切,但在1975到1998年之間,至少為215名大多是老年的患者注射過量的鴉片類藥物。紙包不住火,他因為偽造一名受害人的遺囑,留給自己一些錢,終於露出馬腳:他的女兒是律師,感到懷疑,對他的電腦進行法醫分析(forensic analysis)的結果,發現他回頭竄改患者的病歷,使他的受害人的病情看起來比實際上嚴重得多。很多人知道他很早就熱衷於採用新技術,可惜在技術上還不夠精明,不曉得每竄改一次,都會蓋上時間戳記(順便一提,這是資料能夠揭露隱藏意義的好例子)。
後來,有15具未經火化就埋葬的病患屍體被挖出,在他們體內發現了足以致命的二乙醯嗎啡(也就是海洛因)。希普曼在1999年因15起謀殺案而受審,但他選擇不作任何辯護,不曾在審判時吐露一個字。他被判有罪,終身監禁,當局也開啟公開調查,除了被審判的罪行,他可能還犯了哪些罪,以及是否可能早點逮捕他。許多統計學家受傳喚在公開調查中提供證據,我也是其中之一。結論是他肯定謀殺了215名病患,甚至可能要再多加上45名。2
本書的重點是:運用統計科學(statistical science)來解釋當我們想更了解這個世界時會碰到的問題。其中一些問題將以方框顯示。為了深入了解希普曼的行為,自然而然要問的第一個問題是:
希普曼是殺害哪一種人,以及他們何時死亡?
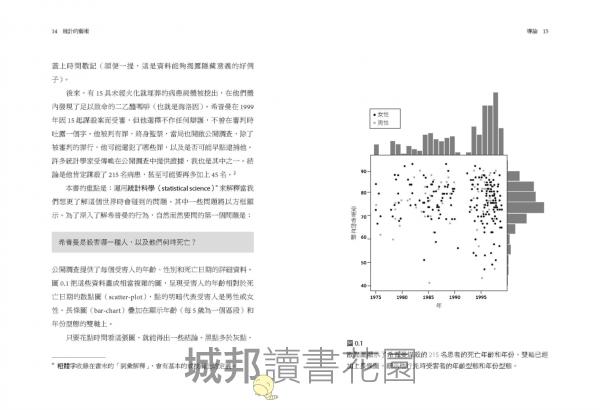
公開調查提供了每個受害人的年齡、性別和死亡日期的詳細資料。圖0.1把這些資料畫成相當複雜的圖,呈現受害人的年齡相對於死亡日期的散點圖(scatter-plot),點的明暗代表受害人是男性或女性。長條圖(bar-chart)疊加在顯示年齡(每5歲為一個區段)和年份型態的雙軸上。
只要花點時間看這張圖,就能得出一些結論。黑點多於灰點,所以受害人以女性居多。右方的長條圖顯示,大多數受害人是70幾歲和80幾歲,但從點的散布來看,發現受害人雖然起初都是老年人,但隨著時間的流逝,一些年紀較輕的案例逐漸出現。上方的長條圖清楚顯示1992年左右的缺口沒有人受害。後來發現,在那之前,希普曼一直和其他的醫生共同執業,但隨後可能因為覺得被人懷疑,於是離去自行開業。在這之後,如上方的長條圖所示,他下手的速度加快了。
針對公開調查確認的受害人進行分析,讓人對於他的殺人方式產生進一步的疑問。死亡證明書記錄了推定是受害人的死亡日期、時間資料,給了一些統計證據。圖0.2的線形圖比較了希普曼患者的死亡時間和其他當地家庭醫生患者樣本的死亡時間。這個型態(pattern)不需要細膩的分析:結論有時可謂「醍醐灌頂」,因為它讓你恍然大悟。希普曼的病人絕大多數在中午之後不久死亡。
資料無法告訴我們,為什麼他們經常在那個時間死去,但是進一步的調查顯示,希普曼總是在午餐後到患者的家中訪問,通常和年長病人獨處,並且提議給他們打針,說打了之後,身體會比較舒服,事實上卻是注射致命劑量的二乙醯嗎啡:等到患者在他面前安詳死去,他便更改他們的病歷,看起來像是預期中的自然死亡。主持公開調查的珍妮特.史密斯夫人(Dame Janet Smith)後來說:「我仍然覺得有一股說不出的可怕,他竟然能夠日復一日裝作是濟世仁醫,往診袋卻裝著奪人性命的武器,實在讓人有說不出口、難以置信、不可思議的毛骨悚然……他只要理所當然地把武器拿出來。」
他也冒了若干風險,因為只要驗一次屍,就會事跡敗露,但由於病人們年事已高,看起來都是自然死亡,所以沒有一位驗過屍。他不曾解釋犯下這些謀殺案的理由:沒在審判中提出任何證詞、從未向包括家人在內的任何人談論自己的不法行為。他最後在獄中自盡,剛好讓妻子及時領取他的養老金。
我們可以將這種來回反覆的探索性工作,視為「法醫」統計學,而在本案中,確實是如此。不必用到數學,不必高談闊論深奧的理論,只要尋找可能帶出更多有趣問題的型態就行。希普曼不法行為的細節,是使用每一個別案件的特定證據確定的,但是這個資料分析,有助於整體性地理解他是如何行兇的。
本書稍後會在第10章,探討正式的統計分析能否幫助我們早點逮捕希普曼。在此同時,希普曼的故事充分展現了使用資料幫助我們了解世界,並且做出更好判斷的巨大潛力。這就是統計科學。
將世界化為資料
要以統計方法探討希普曼的犯罪行為,我們有必要從和他有關的一長串個別悲劇後退一步來看。人的生和死,所有的個人獨特細節,都必須化簡為一組事實和數字,能在圖上計數和繪製。乍看之下,這似乎冷酷而沒人性,但是如果我們要用統計科學來照亮世界,我們的日常經驗就必須化為資料,而這表示要將各種事件分類和標記、記錄測量值、分析結果並傳達我們的結論。
但是單單分類和標記,就是嚴峻的挑戰。下面這個基本問題,關心我們的環境的人應該都會感興趣:
地球上有多少棵樹?
在我們能開始思考如何回答這個問題之前,首先必須處理一個相當基本的問題。什麼是「樹」?你可能覺得,一看到樹,你就知道那是樹,但是你的判斷可能和別人大不相同,因為他們或許認為那是灌木或矮樹叢。因此,要將經驗轉化為資料,我們必須從嚴格的定義做起。
我們發現,「樹」的正式定義是胸高直徑(diameter at breast height;DBH)夠大,有木本莖的植物。美國國家森林局(US Forest Service)規定植物的DBH大於5吋(12.7公分),才能正式稱之為樹,但是大多數國家使用的DBH是10公分(4吋)。
但我們沒辦法親自走遍整個地球,測量每一棵木本植物,計算符合以上所說標準的植物有多少。因此,探究這個問題的研究工作者,採用更務實的方法:他們先找一連串有同類地景的區域(稱為生物群落〔biome〕),計算每平方公里發現的樹木平均數量。他們接著利用衛星成像技術,估計每一類生物群落覆蓋的地球總面積,以及展開一些複雜的統計建模,最後估計地球上共有3.04兆(即3,040,000,000,000)棵樹。聽起來好像很多,但他們估計以前的樹木數量是這個數字的兩倍。*
(*這個數字的誤差範圍是0.1兆,表示研究工作者相信真實數字在2.94兆到3.14兆之間(我承認,鑑於建模中的許多假設,這個數字可能讓人感覺過於準確)。他們也估計每年人們砍伐150億(15,000,000,000)棵樹,以及自有人類文明以來,地球已經少掉46%的樹。)
如果各國的主管當局連對樹的看法也有出入,那麼要確定更為含糊的概念想必更困難。舉一個極端的例子來說。從1979年到1996年,英國官方的「失業」定義至少更動了31次。國內生產毛額(Gross Domestic Product;GDP)的定義也不斷修訂,例如2014年將非法販毒和賣淫納入英國的GDP中;估計值使用了平常不會用到的一些資料來源(例如針對性交易服務給予評等的評論網站Punternet),以取得各種不同活動的價格資料。
連我們最個人私密的感覺,也可以編碼,進行統計分析。2017年9月結束的一年,有一項調查詢問15萬英國人:「整體而言,你昨天覺得多幸福?」從0到10的尺度,他們的平均回答是7.5,比2012年的7.3要好,這可能和2008年金融崩潰之後,經濟有些復甦有關。50到54歲之間的受訪者幸福感分數最低,70到74歲之間的受訪者幸福感分數最高。這是英國的典型型態。
這些例子告訴我們,統計學在某種程度內,總是要根據人的判斷來建構;如果認為個人經驗即使十分複雜,也能一清二楚地編碼,放進電子試算表或其他的軟體中處理,那顯然是癡心妄想。雖然定義、計數和測量我們本身和周遭世界的特徵有其挑戰性,但那仍然只是資訊,而且只是真正了解世界的起點。
資料作為這種知識的來源,受到兩大限制。首先,它幾乎總是不能完美地測量我們十分感興趣的事物:以0到10的尺度問人們上個星期有多幸福,幾乎無法具體而微呈現全國的情感福祉。其次,我們選擇測量的任何事物,都會因地、因人、因時而異,而我們的問題就是要從顯然是隨機變異性(variability)中提取有意義的見解。
幾個世紀以來,統計科學一直面對上述的雙重挑戰,並在理解世界的科學嘗試中扮演領導角色。它提供基礎,讓我們解讀始終不完美的資料,好從讓所有的人顯得獨特的背景變異性(background variability)中,將重要的關係區別出來。但世界總是在變動,人們會問新的問題,也會有新的資料來源可用,所以統計科學也必須改變。
人們一直在計數和測量,但是正如我們將在第8章提到的,現代統計學作為一門學科,實際上是從1650年代開始,因為布萊茲.帕斯卡(Blaise Pascal)和皮埃爾.德.費馬(Pierre de Fermat)首次正確理解了機率的概念。有了這個處理變異性的堅實數學基礎,進展就非常快了。結合人們死亡年齡的資料之後,機率論為計算退休金和年金提供了堅實的基礎。科學家掌握了機率論可以如何處理測量的變異性之後,天文學產生了革命性的進展。維多利亞時代的愛好者迷上了收集人體(以及其他一切事物)的資料,使得統計分析與遺傳學、生物學、醫學建立起緊密的關係。然後到了20世紀,統計學變得更偏重數學,而且不幸的是,對許多學生和實務工作者來說,統計學相當於一大堆統計工具的機械應用。許多統計工具都是以古怪、好爭辯的統計學家的姓名命名,本書稍後將會提到。
將統計學視為一包基本「工具組」的一般觀點,正面臨重大的挑戰。首先,我們置身於資料科學(data science)的時代,從交通監視器、社群媒體貼文和網際網路購物等例行性來源(routine source)收集大量和複雜的資料組,並且用於優化交通路線、定向廣告(targeted advertising)或購物推薦系統等技術創新的基礎。我們會在第6章討論根據「巨量資料」(big data)的演算法(algorithm)。統計學的訓練,加上資料管理、程式設計和開發演算法的技能,以及適當地了解統計學這門學科,已成為資料科學家的必備條件。
傳統統計觀點遭遇的另一挑戰,是科學研究的數量大增,尤其是在生物醫學和社會科學的領域,以及必須在高排名期刊發表論文的壓力。這導致人們懷疑某些科學文獻的可靠性、許多「科學發現」無法被其他研究人員再現,例如一個人擺出「高權勢姿勢」(power pose)的自信模樣,能否引起荷爾蒙和其他方面的變化,就引起很大爭議。標準統計方法的不當使用,已引起許多人質疑將造成科學的可再現性或複製性危機。
隨著大量的資料組和容易使用的分析軟體越來越多,有些人可能認為現在比較不需要接受統計方法方面的訓練了。這種看法極其天真無知。由於可使用的巨量資料愈來愈多,以及科學研究的數量和複雜度增加,讓我們更難得出適當的結論,因此,統計學的技能其實越來越重要。資料更多,表示我們更需要留意什麼證據才真正有價值。
例如,針對從例行性資料擷取的資料組進行深入分析,由於資料來源內含的系統性偏差,以及明明做了許多分析,卻只報告看起來最有趣的結果(這種做法有時稱為「資料捕撈」〔data-dredging〕),可能會提高錯誤研究結果的可能性。為了能夠批判已發表的科學研究,甚至每天所接觸的媒體報導,我們應該能敏銳地察覺選擇性報導的危險、科研成果應該要能由獨立研究人員重複檢驗,並察覺斷章取義、過度解讀單一研究結果的危險。
所有這些見解,可以歸納為資料素養(data literacy)一詞,代表我們不只能對現實世界的問題展開統計分析,也能理解和批判其他人運用統計學所得出的任何結論。但是要提升資料素養,需要改變統計學的教學方式。
關於本書
本書以解決現實世界中的問題為開端,介紹各種統計觀念。其中有些觀念看起來很明顯易懂,但有些比較隱晦,可能需要費些心力,但不必用到數學技巧。本書和傳統的教科書相比,偏重於概念性問題,不著重技術細節,而且只提到幾個並不困難的公式(在書末的「詞彙解釋」有進一步說明)。軟體是資料科學和統計學工作的重要部分,但不是本書的重點——R和Python都很容易找到免費的線上教材。
在方框中特別凸顯的問題,某種程度上都能透過統計分析來解答,雖然問題的範疇相去甚遠。有些是重要的科學假說,例如希格斯玻色子(Higgs boson)是否存在,或者是否真有令人信服的證據,證明超感官知覺(extra-sensory perception;ESP)存在。還有一些是關於健康照護的問題,例如病人較多的醫院是否有比較高的存活率,以及篩檢卵巢癌是否有好處等。有時我們只想估計數量,例如培根三明治的致癌風險、英國人一生中的性伴侶數目,以及每天服用他汀類(statin)藥物的效益。
還有一些有趣的問題,例如確認「鐵達尼號」(Titanic)上最幸運的生還者;能否早一點逮捕希普曼;以及評估在萊斯特(Leicester)停車場發現的骨骸,確實是英格蘭國王理查三世(Richard III)的可能性。
本書是為兩種人而寫:一種是想要尋找非技術性的、介紹統計學基本概念的入門書的統計學學生;還有,希望更了解在工作及日常生活中碰到的統計問題的一般讀者。我的重點在於聰明、審慎地運用統計學:數字看起來可能像是冷硬的事實,但是要測量樹木、幸福和死亡,需要以精巧而審慎的手法去處理它們。
統計學能使我們清楚了解所面對的問題和得到某些見解,但人們總是知道如何濫用它們,方法通常是極力吹捧、或是設法引人注意某個意見。針對一項統計聲明能夠去評估其可信度,這種能力似乎已成為現代世界的關鍵技能,但願本書能夠幫助人們質疑日常生活中遇到的各種數字。
延伸內容
【專家好評】
史匹格哈特可能是世界上最出色的統計溝通大師……《統計的藝術》值得拜讀和學習。我讀過,受益良多。
──提姆.哈福德(Tim Harford),《親愛的臥底經濟學家》(The Undercover Economist)作者
如果你想要培養看清真實世界的技能,並且誠實且嚴肅地告訴別人它的真實面貌,那麼這是你該讀的書。
──邁克爾.布拉斯特蘭德(Michael Blastland),《如何用數字唬人:用常識看穿無所不在的數字陷阱》(The Tiger That Isn’t)共同作者
威爾斯(H.G. Wells)說的『統計思想有一天會像讀寫一樣,成為高效率公民必備的能力』這句話經常為人引用。那一天肯定已經到了。這本精彩好書提供非技術性和生動有趣的敲門磚,介紹統計思想的基本工具。威爾斯一定讚許有加。
──阿德里安.史密斯爵士(Sir Adrian Smith)教授,英國皇家學會會士,艾倫.圖靈研究所(Alan Turing Institute)董事
即使具有統計專長的人,也能在本書找到不少深具啟發性的文字,因為史匹格哈特思緒清晰,溝通能力卓越,經驗豐富。這是值得一般大眾閱讀的精心力作。
──多蘿西.畢曉普(Dorothy Bishop),牛津大學教授
現代統計學深入淺出的出色踏腳石。
──大衛.漢德(David J. Hand),《不大可能法則》(The Improbability Principle)作者編輯推薦
【編輯推薦】好統計,不學嗎?
近兩年的疫情期間,我們接觸到可能有史以來最多的統計數字。是的,統計學就是離現實生活很近的一門學問,就連做篩檢的「偽陽性」問題、開發疫苗需要做的「臨床隨機試驗」、試驗的方式有「單盲」、「雙盲」、「三盲」等等,這些也都是統計學的內容。
雖然在疫情當中,少不了政治攻防和口水戰,每個人也有個自的壓力,但也是一個好機會,好好來學一點統計學。
這本《統計的藝術:如何從數據中了解事實,掌握世界》,由知名的英國劍橋大學的統計學教授大衛.史匹格哈特所寫,但他不吊書袋,盡量讓讀者容易進入情境,而且很會說故事;恰好他的專長之一就是醫療統計學,因此書中也有一些醫療方面的例子;他這本書,也是希望寫給想更了解日常生活中所碰到的統計問題的一般讀者,因此這本書由淺入深,慢慢讓人想繼續讀下去。
如果是對於科學研究、商業(如大數據、人工智慧、演算法)有興趣的讀者,這本書都會探討到。媒體容易為了點閱率而使用聳動的標題,或偷換概念和數據,這也是作者會著墨的部分。
好統計,不學嗎?更多編輯推薦收錄在城邦讀饗報,立即訂閱!GO
作者資料
大衛.史匹格哈特 David Spiegelhalter
大衛.史匹格哈特爵士是英國的統計學家,劍橋大學統計實驗室(Statistical Laboratory)的溫頓風險與證據溝通中心(Winton Centre for Risk and Evidence Communication)主任。他是他所鑽研領域中最常被引用、且最具影響力的研究工作者之一,並獲選為2017-18年皇家統計學會(Royal Statistical Society)總裁。












注意事項
- 若有任何購書問題,請參考 FAQ